索引类型:
普通索引:最基本的索引,没有任何限制
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
主键索引:它 是一种特殊的唯一索引,不允许有空值。
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
索引结构: B-tree索引 哈希索引 全文索引
不要使用索引情况:
区分度不是很大的字段
频繁更新的字段
字符串类型的字段 或者 文本类型的字段
不在where列中出现的索引
索引失效:
* 查询列中有函数计算
* 查询列中有模糊查询,"%cloum","%cloum%",可以使用"cloum%" 代替。实在用这个索引,新增一列(使用`LOCATE` `POSITION`函数也可以加索引),存储该字段的反转。比如原字段是abcd,取反存储为dcba,查询%bcd改成查dcb%
* 如果查询条件中有or, 索引会失效,除非所有条件都加上索引
* 使用不等于(!= 或者 <>)
* is null 或者 is not null
* 字符串不加引号,会导致索引失效
* 没有最左原则
索引和锁:
加锁的过程要分有索引和无索引两种情况,比如下面这条语句
update user set age=11 where id = 1
id 是这张表的主键,是有索引的情况,那么 MySQL 直接就在索引数中找到了这行数据,然后干净利落的加上行锁就可以了。
而下面这条语句
update user set age=11 where age=10
表中并没有为 age 字段设置索引,所以, MySQL 无法直接定位到这行数据。那怎么办呢,当然也不是加表锁了。MySQL 会为这张表中所有行加行锁,没错,是所有行。但是呢,在加上行锁后,MySQL 会进行一遍过滤,发现不满足的行就释放锁,最终只留下符合条件的行。虽然最终只为符合条件的行加了锁,但是这一锁一释放的过程对性能也是影响极大的。
聚集索引和普通索引
对于mysql来说聚集索引就是主键索引,聚集索引的叶子节点存储记录,普通索引的叶子节点存储存储主键值
回表
聚集索引PRIMARY KEY 叶子节点存储行记录
普通索引 INDEX index_name (column_list)和unique
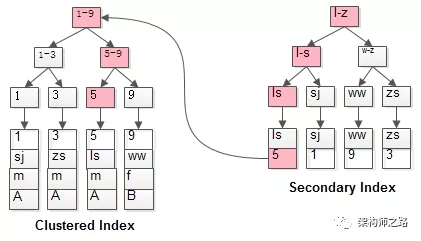
|
|
这个语句需要扫码俩遍索引树:
- 先通过普通索引定位到主键值
- 在通过聚集索引定位到行记录
这就是所谓的回表查询,先定位主键值,再定位行记录。
索引覆盖
explain的输出结果Extra字段为Using index时,能够触发索引覆盖
select cout(name) from user;如果这个是索引就会索引覆盖- 用联合索引可以避免回表
最左前缀explaintype为all表示全文扫描。type为ref,表示使用非唯一索引扫描或唯一索引扫描
- 只有复合索引才会有所谓的左和右之分
- 查询从索引的最左前列开始并且不跳过索引中的列,通俗易懂的来说就是:带头大哥不能死、中间兄弟不能断

TRIGGER触发器DELIMITER $$
CREATE
TRIGGERjony_keer.ins_accountAFTER INSERT
ONjony_keer.t_account
FOR EACH ROW BEGIN
INSERT INTOt_user(userid,cellphone,account_psd) VALUES (new.account_id,new.cellphone,new.account_psd);
END$$
DELIMITER ;mysql解释器根据‘;’来结束读取命令执行命令,在多个‘;’号时,解释器不知到在哪一句结束读取命令执行命令,而delimiter的作用是,将sql结束读取命令并执行命令的标志,替换成delimiter后的标志(在本文是‘//’),这样只有当‘//’出现之后,mysql解释器才会执行这段语句。
存储过程和函数
主要区别就是函数必须有返回值(return),并且函数的参数只有IN类型而存储过程有IN、OUT、INOUT这三种类型。
MySQL 事务都是指在 InnoDB 引擎下,MyISAM 引擎是不支持事务的
事务具有: 原子性 一致性 隔离性 持久性, 随便一个
update都能是个事务select @@tx_isolation;来查当前数据的隔离级别- 读未提交(read uncommitted)
- 读提交(read committed)
- 可重复读(repeatable read)
串行化(serializable)
一. 读未提交是不加锁的,连
脏读(数据可能回滚)都无法解决。二. 读提交就是事务只能读到其他事务调用 commit 命令之后的数据,能解决
脏读,不能解决可重复读(事务中修改条件数据),幻读(事务中加减条件数据)。三. 可重复读(mysql默认读)是指,事务不会读到其他事务对已有数据的修改,及时其他事务已提交,也就是说,事务开始时读到的已有数据是什么,在事务提交前的任意时刻,这些数据的值都是一样的。 解决了
可重复读,实际也解决了幻读。解决方法是:
- 版本快照解决
可重复读,事务开始的读叫当前读,事务中用快照读。 间隙锁解决
幻读,通过索引锁范围,保证添加删除新的会等待四. 串行化是4种事务隔离级别中隔离效果最好的,解决了脏读、可重复读、幻读的问题,但是效果最差,它将事务的执行变为顺序执行,与其他三个隔离级别相比,它就相当于单线程,后一个事务的执行必须等待前一个事务结束
结语: 通常,对于绝大多数的应用程序来说,可以优先考虑将数据库系统的隔离级别设置为读已提交(Read Committed),这能够在避免脏读的同时保证较好的并发性能。尽管这种事务隔离级别会导致不可重复读、幻读和第二类丢失更新等并发问题,但较为科学的做法是在可能出现这类问题的个别场合中,由应用程序主动采用悲观锁或乐观锁来进行事务控制。
分布式事务
两段提交
协调者先询问参与者事务是否执行成功,参与者向协调者返回成功。协调者再发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。
假如在第一阶段有一个参与者返回失败,那么协调者就会向所有参与者发送回滚事务的请求,即分布式事务执行失败。
补偿事务
针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。例如:
1.首先在 Try 阶段,要先调用远程接口把 Smith 和 Bob 的钱给冻结起来。
2.在 Confirm 阶段,执行远程调用的转账的操作,转账成功进行解冻。
3.如果第2步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法 (Cancel)。
本地消息表
本地写业务数据后,记录本地消息队列再发到kafka,转发成功再删除本地消息队列。另一方读取kafka消息队列并处理